
GitHub를 참고하시면 CODE와 다양한 페이퍼 리뷰가 있습니다! 아래 링크를 참조하십시오.
(+별표와 팔로우는 사랑입니다..!)
https://github.com/kalelpark/Awesome-ComputerVision
GitHub – kalelpark/Awesome-ComputerVision: 멋진 컴퓨터 비전
멋진 컴퓨터 비전. GitHub에서 계정을 생성하여 kalelpark/Awesome-ComputerVision 개발에 기여하십시오.
github.com
추상적인
최근의 방법은 두 이미지에서 얻은 임베딩 벡터 간의 관계를 찾으려고 합니다. VICReg임베딩에 두 개의 정규화 용어를 개별적으로 적용하여 정보 접힘을 방지하는 방법을 제안합니다. VICReg에는 분기, 배치 정규화, 기능 측면, 출력 등이 필요하지 않습니다.

VICReg: 직감
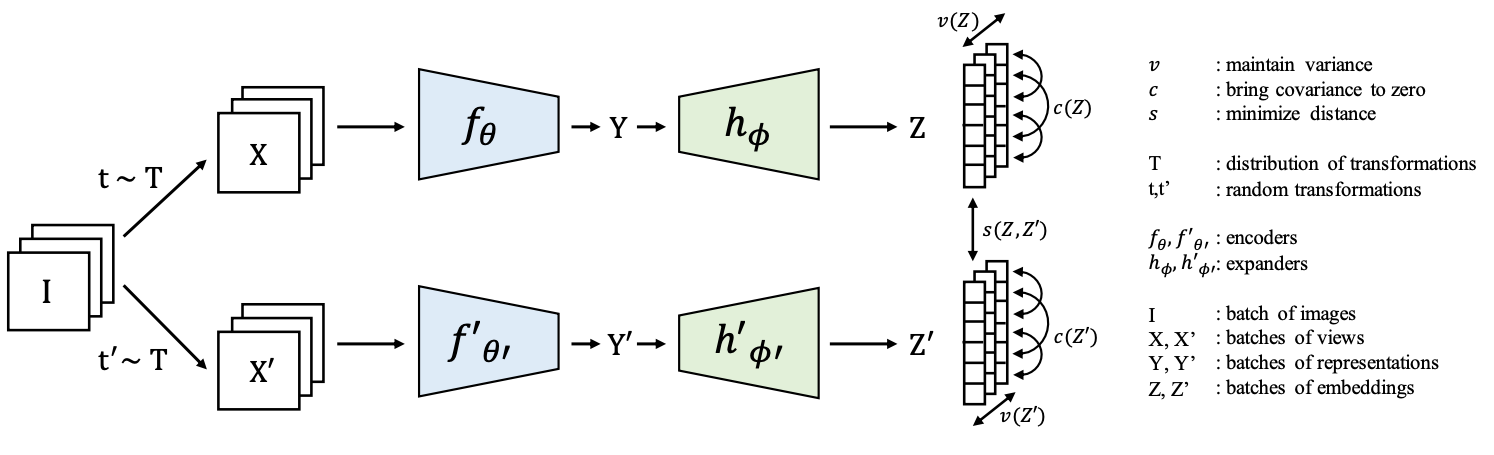
동일한 이미지에서 얻은 임베딩 벡터는 최소화되고 일괄 임베딩 변수의 분산은 임계값 이상으로 유지됩니다. 공분산은 0이 됩니다. 임베딩에는 3개의 완전 연결 레이어가 사용됩니다.이름에서 알 수 있듯이 이
분산, 불변 및 공분산을 나타냅니다.
불변성: 임베딩 벡터 사이의 거리를 나타냅니다.
분산: 임베딩에서 각 변수의 표준 편차를 임계값 이상으로 유지하는 데 사용됩니다.
공분산: 모든 임베딩 변수 사이의 쌍별 공분산을 0으로 그리는 데 사용됩니다.
내장 변수 간의 역 상관관계로 사용되며 상관관계가 높은 정보가 무너지는 것을 방지합니다.
* 이 논문의 주요 기여는 다음과 같습니다.
분산 보존 항에서 임베딩 벡터가 0으로 축소되는 것을 방지합니다.
공분산은 BarlowTwins 방법을 사용하고 정보가 무너지는 것을 방지합니다.
다시 말하지만, 그것은 많이 언급하지 않습니다.
– 두 브랜치의 가중치를 공유할 필요도 없고, 동일한 아키텍처를 요구하지도 않으며,
입력은 동일한 특성을 가집니다.
– 메모리 뱅크, 비교 샘플, 대량 배치 불필요
– 배치 또는 기능 정규화가 필요하지 않습니다.
– 벡터 양자화나 예측 모듈이 필요하지 않습니다.
관련된 일
대조 학습, 클러스터링 방법, 증류 방법, 정보 극대화 방법
말하는
VICReg: 세부 정보
VICReg는 조인트 임베딩 기반 아키텍처입니다. 여기에서 인코더는 두 가지 역할을 합니다.
두 표현 간의 차이점 정보를 제거합니다. (불변 항목으로 이해할 수 있음)
비선형성을 확장합니다. 임베딩 벡터 간의 역상관을 얻을 수 있습니다.

그런 다음 위의 3단계를 계속 진행합니다.
방법


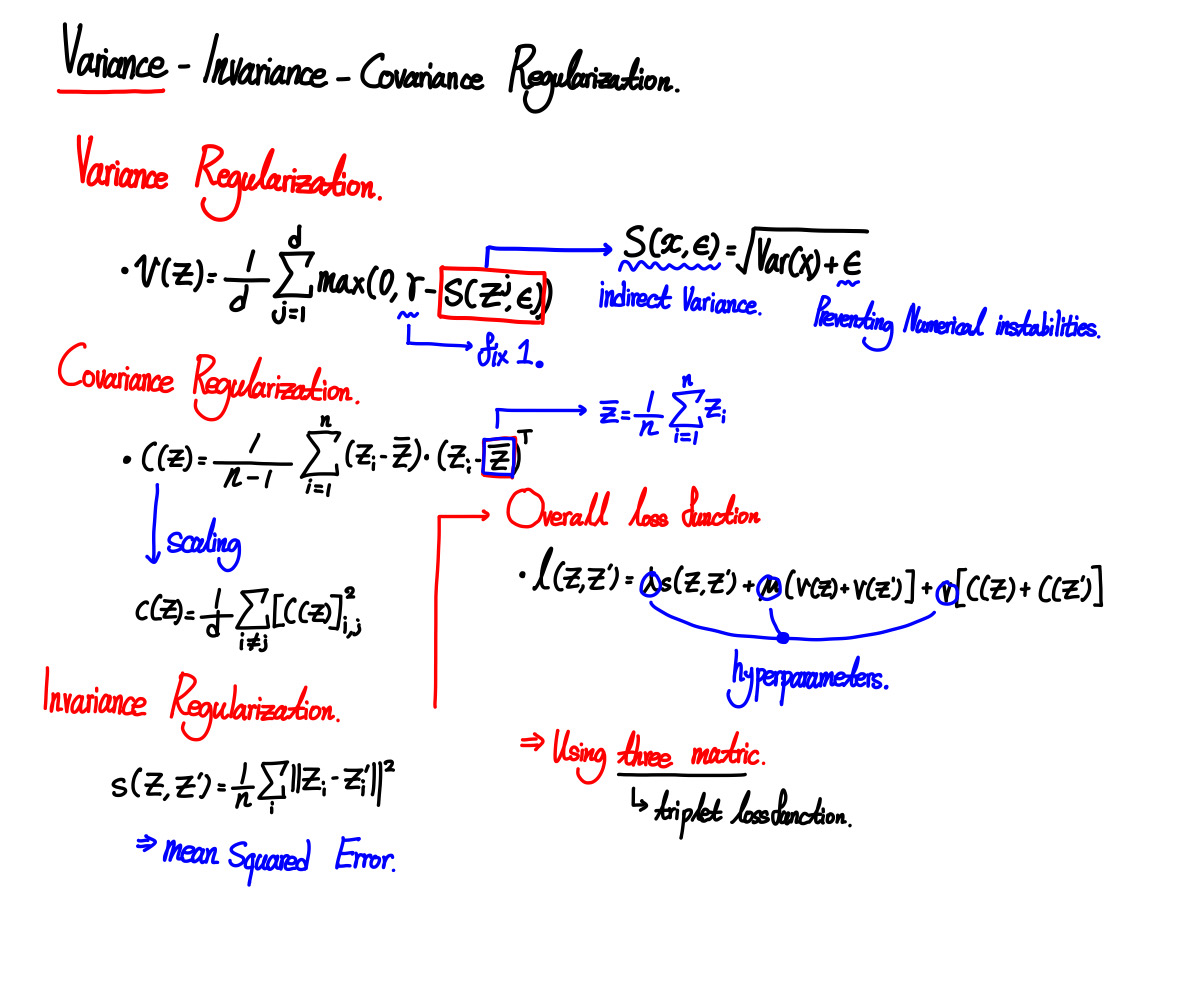
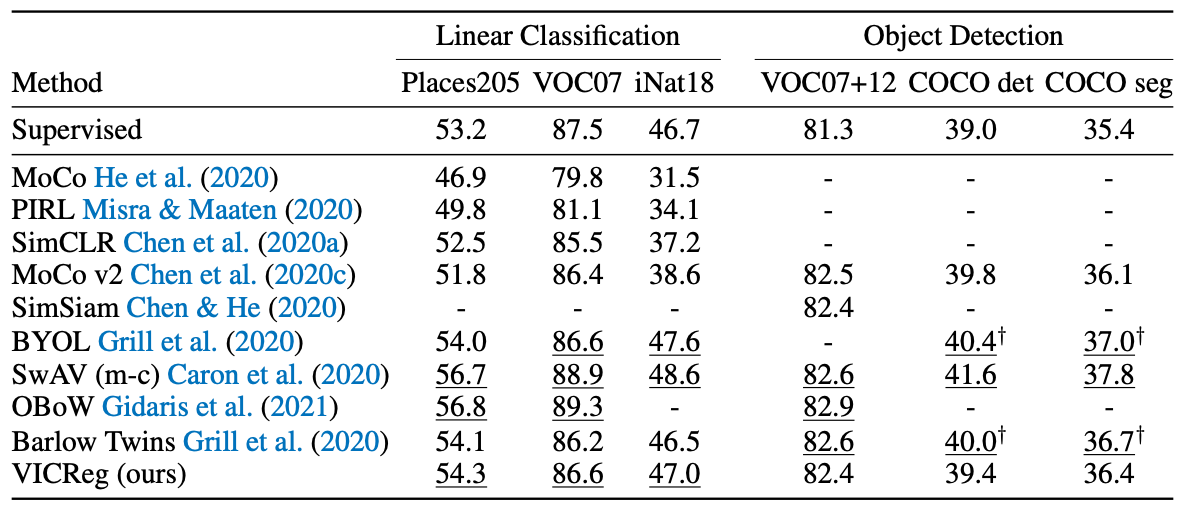
실험
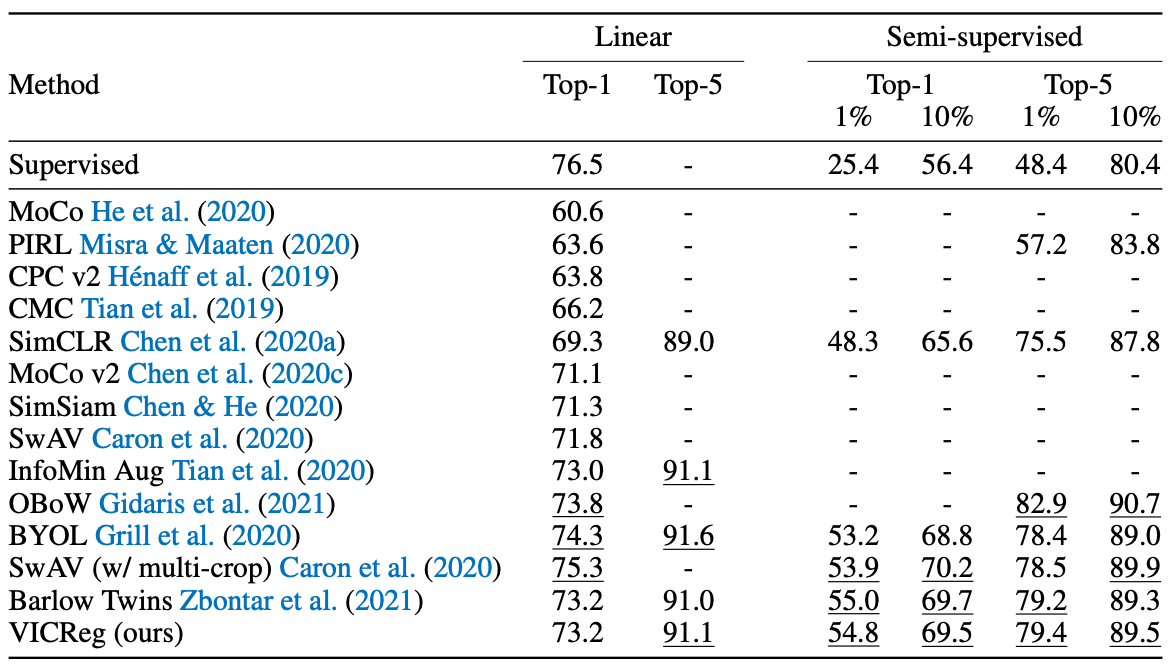
구현하다
x = self.projector(self.backbone(x))
y = self.projector(self.backbone(y))
repr_loss = F.mse_loss(x, y)
x = torch.cat(FullGatherLayer.apply(x), dim=0)
y = torch.cat(FullGatherLayer.apply(y), dim=0)
x = x - x.mean(dim=0)
y = y - y.mean(dim=0)
std_x = torch.sqrt(x.var(dim=0) + 0.0001)
std_y = torch.sqrt(y.var(dim=0) + 0.0001)
std_loss = torch.mean(F.relu(1 - std_x)) / 2 + torch.mean(F.relu(1 - std_y)) / 2
cov_x = (x.T @ x) / (self.args.batch_size - 1)
cov_y = (y.T @ y) / (self.args.batch_size - 1)
cov_loss = off_diagonal(cov_x).pow_(2).sum().div( self.num_features)
+ off_diagonal(cov_y).pow_(2).sum().div(self.num_features)
loss = ( self.args.sim_coeff * repr_loss + self.args.std_coeff * std_loss
+ self.args.cov_coeff * cov_loss)
return loss
class FullGatherLayer(torch.autograd.Function):
"""
Gather tensors from all process and support backward propagation
for the gradients across processes.
"""
@staticmethod
def forward(ctx, x):
output = (torch.zeros_like(x) for _ in range(dist.get_world_size()))
dist.all_gather(output, x)
return tuple(output)
@staticmethod
def backward(ctx, *grads):
all_gradients = torch.stack(grads)
dist.all_reduce(all_gradients)
return all_gradients(dist.get_rank())결론적으로
이 논문에서는 triplet 기반 VICReg를 소개합니다. VICReg는 많은 다운스트림에서 SOTA를 구현했습니다. (그런 이유로…?)
분산과 표준편차를 근사하는 것이 참신해 보여서 받아들여지는 것 같습니다.
인용하다
VICReg: 자기 지도 학습을 위한 분산-불변-공분산 정규화
이미지 표현 학습을 위한 최근의 자기 감독 방법은 동일한 이미지의 다른 보기에서 포함된 벡터 간의 일치를 최대화하는 데 기반합니다. 인코더가 상수 벡터를 출력하면 간단한 솔루션을 얻을 수 있습니다.이 충돌
arxiv.org